
NVIDIA DGX™ A100은 모든 AI 워크로드를 위한 유니버설 시스템으로, 세계 최초의 5페타플롭스 AI 시스템을 통해 유례없는 컴퓨팅 밀도, 성능 및 유연성을 제공합니다. NVIDIA DGX A100은 세계에서 가장 최첨단의 가속기인 NVIDIA A100 Tensor 코어 GPU를 탑재하여 엔터프라이즈 기업들이 NVIDIA AI 전문 가의 직접적인 지원과 함께 트레이닝에서 추론, 분석에 이르기까지 배포하기 쉬운 통합 AI 인프라를 구축할 수 있게 합니다.


Ampere Architecture
AI 인프라를 위한 유니버설 시스템
과학자, 연구자, 엔지니어와 같은 이 시대의 다빈치와 아인슈타인들이 AI와 고성능 컴퓨팅(HPC)을 통해
세계에서 가장 중요한 과학, 산업, 빅 데이터 과제를
해결하려 노력하고 있습니다.
기업들과 전체 산업들은 온프레미스와 클라우드 모두에서 대규모 데이터 세트로부터 새로운 인사이트를 추출하기 위해 AI의
힘을 활용하려고 합니다. 탄력적 컴퓨팅의 시대에 맞게 설계된 NVIDIA Ampere 아키텍처는 이전 세대 대비
혁신적인 성능 도약으로 모든 규모에서 비교할 수
없는 가속화를 제공하여 혁신가들이 중요한 연구 과제를 수행할 수 있도록 지원합니다.
세계 최고의 성능과 탄력성을
갖춘 데이터센터의 핵심
540억 개의 트랜지스터로 제작된 NVIDIA Ampere는 7나노미터(nm) 칩으로 획기적인 6개의 핵심 혁신을 선보입니다.
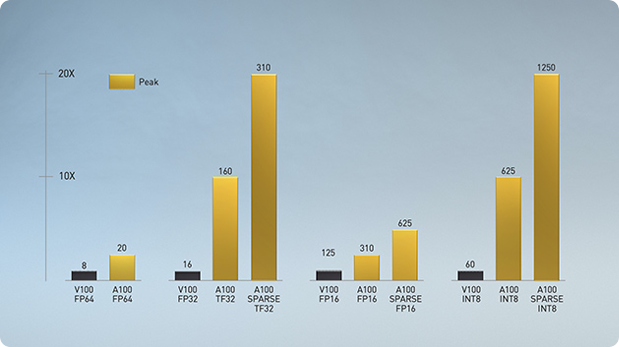


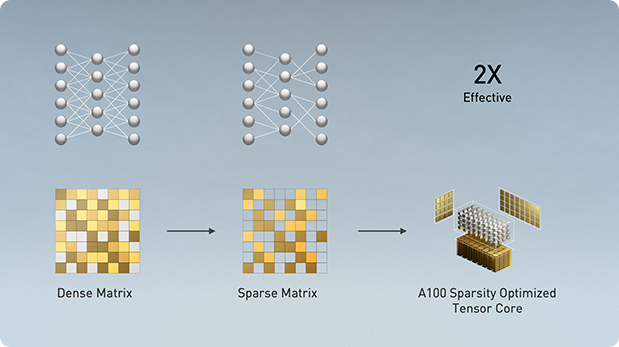


-

- 모든 AI 인프라를 위한
유니버설 시스템 -
분석에서 트레이닝과 추론에 이르기까지 DGX A100은 모든 AI 인프라를 위한 유니버설 시스템
입니다. 컴퓨팅 밀도에 새로운 기준을 제시합니다. 6U 폼 팩터에 5페타플롭스의 AI 성능을 갖추고,
레거시 인프라 사일로를 모든 AI 워크로드에 사용
가능한 단일 플랫폼으로 대체합니다.
-

- DGXperts:
AI 전문가의 지원 -
NVIDIA DGXperts는 지난 10년간 쌓은 풍부한
경험으로 고객이 DGX 투자 가치를 극대화하도록 지원하는 14,000명 이상의 AI 전문가로 구성된
글로벌 팀입니다.
-

- 가장 빠른
솔루션 구축 -
NVIDIA DGX A100은 NVIDIA A100 Tensor 코어 GPU를 탑재한 세계 최초의 시스템입니다.
8장을 A100 GPU를 탑재한 이 시스템은 전례 없는 가속을 제공하며 NVIDIA CUDA-X™ 소프트 웨어와
엔드 투 엔드 NVIDIA 데이터센터 솔루션 스택에
모두 완전히 최적화되어 있습니다.
-

- 전례없는
데이터 센터 확장성 -
NVIDIA DGX A100은 최대 450GB/s의 양방향
대역폭으로 작동하는 내장형 Mellanox 네트워킹을 탑재합니다. 이는 DGX A100을 엔터 프라이즈의 확장 가능한 AI 인프라 청사진인 NVIDIA DGX SuperPOD™와 같은 대규모 AI 클러스터의 기초
빌딩 블록으로 만드는 많은 기능 중 하나입니다.
판도를 바꾸는 성능
-
- 분석
- PageRank
- AI 개발을 촉진하는 심층적인 인사이트 획득
3,000X CPU Servers vs. 4X DGX A100.
Published Common Crawl Data Set: 128B Edges, 2.6TB Graph. -
- 트레이닝
- NLP: BERT-Large
- 더 빠른 트레이닝으로 최첨단 AI 모델 활용
BERT Pre-Training Throughput using PyTorch including (2/3)Phase 1 and
(1/3)Phase 2. Phase 1 Seq Len = 128, Phase 2 Seq Len = 512. V100: DGX-1 with
8X V100 using FP32 precision. DGX A100: DGX A100 with 8X A100 using TF32 precision. -
- 추론
- Peak Compute
- 더 빠른 추론으로 극대화된 시스템을 통해 ROI 증가 활용
CPU Server: 2X Intel Platinum 8280 using INT8. DGX A100: DGX A100
with 8X A100 using INT8 with Structural Sparsity.
더 크고 복잡한 데이터 사이언스 문제를 더 빨리 해결
- 즉시 실행할 수 있는 최적화된 AI 소프트웨어로 지루한
설정 및 테스트가 필요하지 않습니다. - 전례없는 성능으로 더 빠른 반복 작업이 가능한 더 나은
모델을 더 일찍 확인하세요. - 시스템 통합과 소프트웨어 엔지니어링에 시간을 낭비하지 마세요.
규모에 맞는 인프라 배포 및 AI 운용
- 모든 AI 워크로드를 위한 하나의 시스템으로
간소화된 인프라 디자인과 용량 계획을 경험하세요. - 최고의 컴퓨팅 밀도 및 성능을
최소한의 공간에서 달성하세요. - 컨테이너부터 칩까지 층마다 내장된 보안을 활용하세요.
인사이트 확보 시간 단축 및 AI의 ROI 가속화
- 데이터 사이언티스트의 생산성을 증대하고
부가 가치가 없는 노력을 들이지 마세요. - 컨셉에서 프로덕션까지
제품 개발 사이클을 가속하세요. - DGX 전문가가 문제점을 해결할 수 있도록 함께
도와드립니다.

강력한 구성 요소 살펴보기
-
- ❶총 320GB의 GPU 메모리를 탑재한 NVIDIA A100 GPU 8개
- GPU당 NVLink 12개 GPU 간 대역폭 600GB/s
-
- ❷NVSWITCH 6개
- 양방향 대역폭 4.8TB/s 이전 세대보다 2배 더 증가
-
- ❸Mellanox ConnectX-6 VPI HDR InfiniBand/200GB 이더넷 9개
- 최대 450GB/s의 양방향 대역폭
-
- ❹듀얼 64코어 AMD CPU 및 1TB 시스템 메모리
- 3.2배 더 많은 코어로 가장 집약적인 AI 작업 처리
-
- ❺15 TB GEN4 NVME SSD
- 최대 25GB/s의 대역폭 Gen3 NVME SSD보다 2배 빠른 속도

- 1
- 2

- 4
- 5
The Technology Inside NVIDIA DGX A100
- NVIDIA A100 Tensor Core GPU
-
NVIDIA A100 Tensor 코어 GPU는 AI, 데이터 분석 및 고성능 컴퓨팅 (HPC)을 위한
유례없는 가속화를 제공하여 세계에서 가장 까다로운 컴퓨팅 문제를
처리합니다. 3세대 NVIDIA Tensor 코어가 막대하게 성능을 향상하므로 A100 GPU는 수천 개 단위로 효율적으로 확장하거나 Multi-Instance GPU 를 통해 7개의 더 작은 인스턴스로 분할 되어 모든 규모의 워크로드를 가속화할 수 있습니다.

- Multi-Instance GPU (MIG)
- MIG(Multi-Instance GPU) 덕분에 DGX A100의 A100 GPU 8개는 무려 56개의 GPU 인스턴스로 구성될 수 있으며 각 GPU 인스턴스는 고유의 고대역폭 메모리, 캐시, 컴퓨팅 코어로 완전히 격리될 수 있습니다. 이는 관리자가 여러 워크로드를 위해 보장된 서비스 품질(QoS)의 GPU를 적절한 크기로 사용할 수 있게 합니다.
- 차세대 NVLink 및 NVSwitch
-
DGX A100에서 3세대 NVIDIA® NVLink®는 GPU 간의 직접적인 대역폭을
2배인 600GB/s로 증가시키며 이는 PCIe Gen 4의 10배에 달합니다. DGX A100는 이전 세대보다 2배 빠른 차세대 NVIDIA NVSwitch™를 탑재합니다.

- Mellanox ConnectX-6 VPI HDR
InfiniBand - DGX A100은 200GB/s로 작동하는 최신 Mellanox ConnectX-6 VPI HDR InfiniBand/이더넷 어댑터를 탑재하여 대규모 AI 워크로드를 위한 고속 패브릭을 생성합니다.

- 최적화된 소프트웨어 스택
- DGX A100은 AI 조정된 기본 운영 체제, 필요한 모든 시스템 소프트웨어, GPU 가속 애플리케이션, 사전 트레이닝된 모델 및 NGC™의 기타 기능 등 테스트를 거쳐 최적화된 DGX 소프트웨어 스택을 통합합니다.
- 내장형 보안
-
DGX A100은 자체 암호화 드라이브, 서명된 소프트웨어 컨테이너, 안전한 관리 및 모니터링 등
모든 주요 하드웨어 및 소프트웨어 구성 요소를 보호하는
다단계 접근 방식으로 AI 배포를 위한 가장 든든한 보안 방식을 제공합니다.
NVLink and NVSwitch
향상된 멀티 GPU 프로세싱,
속도와 확장성이 향상된 상호 연결의 필요성
AI 및 고성능 컴퓨팅(HPC)에서의 컴퓨팅 수요가 증가함에 따라 GPU 시스템이 함께
하나의 거대한 가속기 역할을 할 수 있도록 GPU 간의
원활한 연결이 가능한 멀티 GPU 시스템에 대한 필요성이 커지고 있습니다.
하지만 표준인 PCIe의 제한된 대역폭으로 인해 병목 현상이
발생하는 경우가 잦습니다.
가장 강력한 엔드 투 엔드 컴퓨팅 플랫폼을 구축하려면 속도와 확장성이 더욱 향상된 상호연결이 필요합니다.

NVLink와 NVSwitch가 함께 작동하는 방식
NVIDIA® NVLink®는 GPU 간 고속 직접 상호 연결입니다. NVIDIA NVSwitch™는 여러 NVLink를 통합함으로써 NVIDIA HGX™ A100과 같은
단일 노드 내에서 올 투 올 GPU 통신을 최대 NVLink 속도로 제공하여 한 차원 높은 상호 연결성을 제공합니다. NVIDIA는 NVLink와
NVSwitch를 조합하여 AI 성능을 효율적으로 여러 GPU로 확장하고 최초의 범산업 AI 벤치마크인 MLPerf 0.6을 획득할 수 있었습니다.
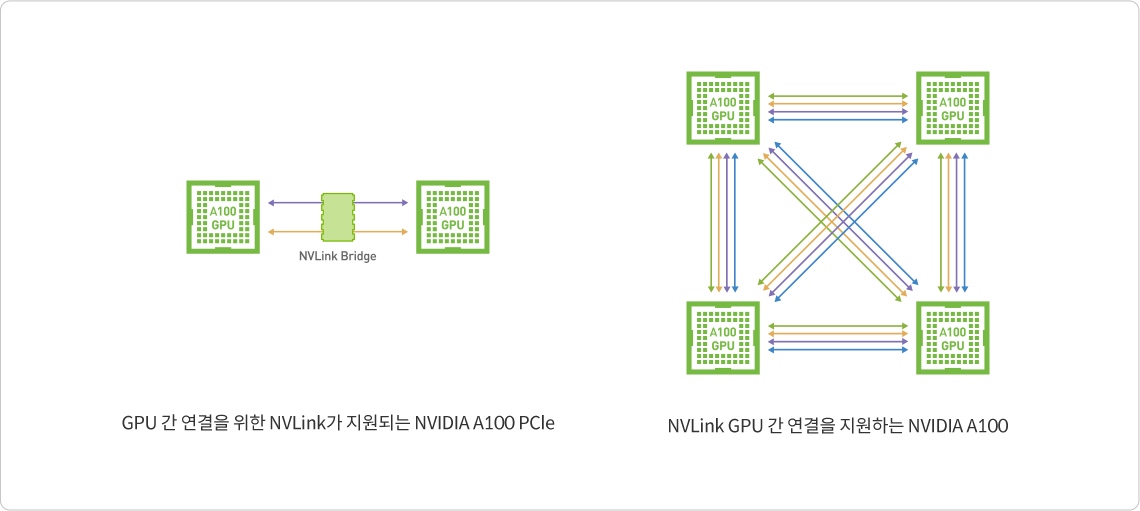
- 시스템 처리량 극대화
- 3세대 NVLINK
-
NVIDIA NVLink 기술은 멀티 GPU 시스템 구성을 위해 더 높은 대역폭
더 많은 링크, 개선된 확장성을 제공함으로써 상호 연결 문제
해결합니다. 하나의 NVIDIA A100 Tensor 코어 GPU는 최대 12개의
3세대 NVLink 연결을 지원하여 600GB/s의 총 대역폭을 구현하며 이
PCIe Gen 4 대역폭의 거의 10배에 해당합니다. NVIDIA DGX™ A100과
같은 서버는 이 기술을 활용하여 초고속 딥 러닝 트레이닝을 위한 더 높은
확장성을 제공합니다.
- NVLink Performance
-
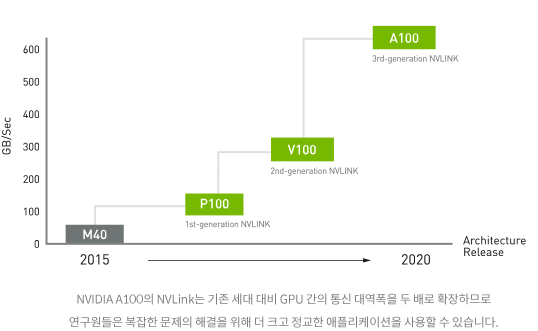
- NVSwitch - 완전히 연결된 NVLink
-
멀티 GPU 시스템 수준에서 PCIe 대역폭이 병목 현상을 일으키는
경우가 잦아 딥 러닝의 신속한 도입은 속도와 확장성이 향상된 상호
연결 기술에 대한 수요를 증가시켰습니다. 딥 러닝 워크로드의 확장을
위해서는 대폭 증가된 대역폭과 감소된 지연 시간이
요구됩니다.
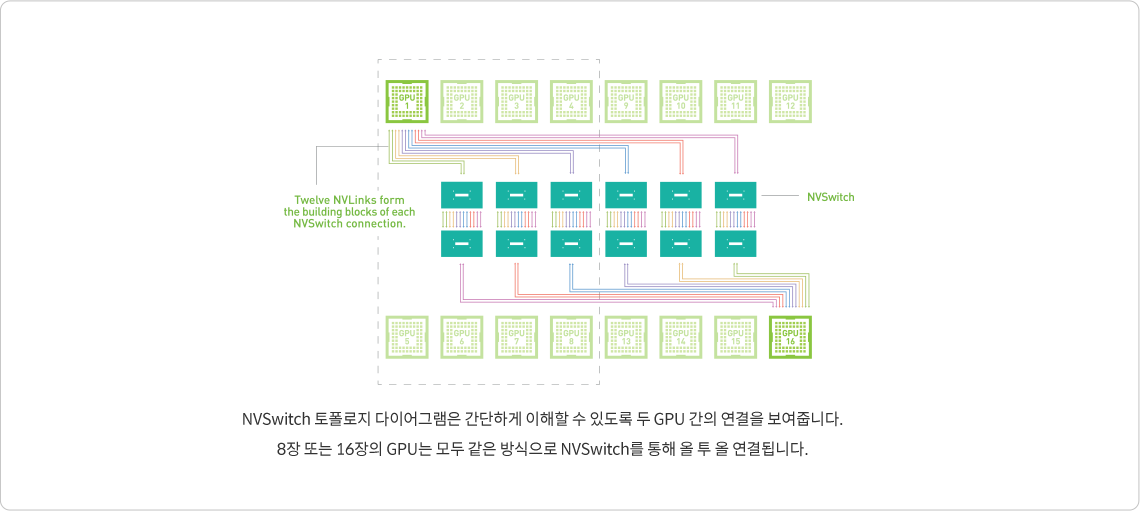
NVIDIA NVSwitch는 이 문제를 해결하기 위해 NVLink의 고급 통신
기능을 기반으로 구축됩니다. 단일 서버에서 더 많은 GPU를 지원하며
이러한 GPU 사이에 완전한 대역폭 연결성을 보장하는
GPU 패브릭으로 딥 러닝 성능을 다음 단계로 끌어올립니다. 각 GPU의 NVLink 12개가 NVSwitch로 완전히 연결되어 올투올(All-to-all) 고속 통신을 지원합니다.

- 비교할 수 없는
성능을 제공하는 완전한 연결 - NVSwitch는 단일 서버 노드에서 8개~16개의 완전히 연결된 GPU를 지원하는 최초의 노드 간 스위치 아키텍처입니다. 2세대 NVSwitch는 놀라운 600GB/s 속도로 모든 GPU 쌍 사이에 동시 통신을 지원합니다. 직접적인 GPU 피어 투 피어(Peer-to-per) 메모리 주소 지정으로 완전한 올 투 올 통신을 지원합니다. 이러한 16장의 GPU는 통합 메모리 공간과 최대 10페타플롭스의 딥 러닝 컴퓨팅 성능을 갖춘 단일 고성능 가속기로 사용될 수 있습니다.
- 가장 강력한 엔드 투 엔드 AI
및 HPC 데이터센터 플랫폼 - NVLink 및 NVSwitch는 완전한 NVIDIA 데이터센터 솔루션의 구성 요소로, 이 솔루션은 하드웨어, 네트워킹, 소프트웨어, 라이브러리, 그리고 NGC™의 최적화된 AI 모델 및 애플리케이션을 통합합니다. 연구원은 가장 강력한 엔드 투 엔드 AI 및 HPC 플랫폼을 통해 실제 결과를 제공하고 솔루션을 프로덕션에 배포하여 모든 규모의 전례 없는 가속화를 제공할 수 있습니다.
| 2세대 | 3세대 | |
|---|---|---|
| 총 NVLink 대역폭 | 300 GB/s | 600 GB/s |
| GPU별 최대 링크 수 | 6 | 12 |
| 지원되는 NVIDIA 아키텍처 | NVIDIA VoltaTM | NVIDIA Ampere Architecture |
| 1세대 | 2세대 | |
|---|---|---|
| 직접 연결이 지원되는 GPU 수 | 최대 16개 | 최대 16개 |
| NVSwitch GPU 간 대역폭 | 300 GB/s | 600 GB/s |
| 총 집계 대역폭 | 4.8 TB/s | 9.6 TB/s |
| 지원되는 NVIDIA 아키텍처 | NVIDIA VoltaTM | NVIDIA Ampere Architecture |
NVIDIA DGX A100 SPECIFICATIONS
|
|
|
|
|
|
|
|
|
|
|
|
|
|